Пока читал книгу “Простое объектно-ориентированное проектирование”, выяснил что у этого же автора есть еще книга и то же решил её прочитать. Вообще, автор еще в 2015 году издал серию(!) книг по тестированию, разработке через тестирование и просто введению по нескольким языкам, включая PHP, Ruby и C, а эта является кульминацией его преподавательского опыта. Так как автор является преподавателем, уже можно сделать некоторые выводы. Например, что в книге будет скорее теория и много ссылок :) Забегая вперед скажу, что уже заказал себе пару книг “по следам”, а несколько нашел в электронном виде, так как они уже не издаются.

Практически в самом начале книги появляется иллюстрация процесса разработки, которая по сути представляет и общее содержание книги, её план, если можно так сказать. Какие-то главы, будут раскрыты не полностью, как минимум по тому что сам по себе материал в них обширный, но в целом книга получилась содержательной. Прикольно то, что в описании фигурируют, цитирую: - “предметное, граничное и структурное тестирование”. При этом я вообще не знаю, что это такое предметное тестирование. Пошел в Вики, там тоже тишина… Уже позже выяснил, что речь идёт о тестировании предметной области (domain testing), термине, который существует, но используется не слишком широко. Дальше в книге эти подходы раскрываются подробнее.
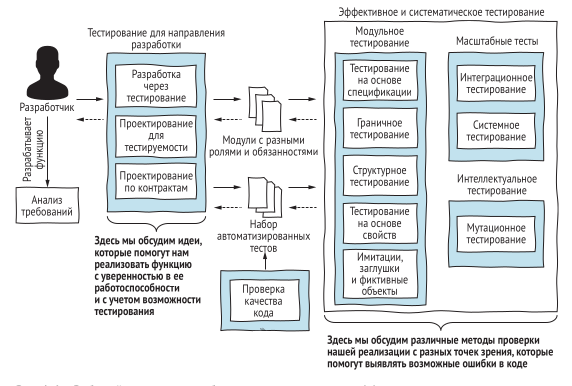
начало понравилось хотя бы последовательностью изложения материала. Да, может быть пример с двумя разработчиками немного наивный, но это мелочи.
Пока читал вступление, встретил упоминания новых для меня инструментов тестирования вроде jqwik. Он предназначен для организации тестирования на основе свойств. Эта методика, как и работа с инструментом будут описаны позже в книге. Понял, что у меня IDE не подсвечивает строки кода, которые покрыты тестами. В итоге разобрался, один плюс в копилку книги :)
Встретил такое определение, как “парадокс пестицидов”. Почитал и понял, что автор использует такое определение, как метафору. В оригинале применение пестицидов активно ухудшает ситуацию, напрямую уничтожая естественных врагов и провоцируя вспышки новых вредителей. Это самосбывающееся пророчество: твое действие делает проблему хуже. В то время, как в определении автора применение одного и того же метода тестирования не ухудшает качество кода. Оно не создает новых классов ошибок. Оно просто становится менее эффективным со временем, потому что его “зона обнаружения” исчерпана. Автор берет основную идею парадокса - «одно и то же средство, применяемое постоянно, теряет эффективность, и нужен комплексный подход».
Так же в первой главе рассматривается “Пирамида тестирования”, в основании которой находятся модульные тесты, как самые простые, быстрые и массовые, а на вершине - end-to-end тесты, как самые сложные. Так как для них надо подготавливать всю инфраструктуру, включая сервисы, с которыми реализована интеграция. По середине расположились интеграционные тесты и системные тесты. В общем-то, ничего нового, но для тех, кто только начинает изучать - знать надо, конечно.
В процессе чтения автор будет предлагать не раз использовать книгу “Делай как в Google. Разработка программного обеспечения”, как “второе мнение” и часто ссылаться на блог Martin Fowler: https://martinfowler.com/.
Во второй главе автор описывает процесс тестирования на основе спецификаций. В процессе встретил прикольный термин, эквивалентные комбинации, и еще три странных: - границы в значениях, точка входа и точка выхода.
Заметил, что зачем-то перевели термин bug, превратив его в “жучка”, что выглядит не очень. Мне кажется, что “баг” - это уже устоявшийся термин, который не нуждается в переводе? Но, ладно… Обратил внимание, что автор группирует несколько тестов в один метод и использует параметризированные тесты. Хорошо, что он сам замечает, что это спорная методика и говорит что подробно обсудит её применение дальше в книге. Мой опыт говорит о том, что и параметризированные тесты, и сгруппированные тесты рано или поздно приходится разбивать. Вообще, классическая структура модульных тестов - это «Arrange-Act-Assert» - «Подготовка-Действие-Проверка», а все остальное от лукавого. Хотя бы по тому, что будет сложнее разбираться в причинах падения тестов, их исправления, да и в целом - сопровождать.
Во всем остальном, материал понравился. Все выглядит разумно, может быть несколько многословно, но для тех, кто только знакомится с тестированием, будет в самый раз.
Следующая была посвящена структурному тестированию на основе анализа исходного кода. Цель - расширить набор тестов, которые были разработаны посредством тестирование на основе спецификаций. В этой главе появляется такое понятие, как оценка покрытия кода тестами и такой инструмент, как JaCoCo. В целом, в этой главе автор рассуждает о том, как качественно охватить пути кода. О том, как относится к показателю покрытия кода, например что 100% охвата - это не гарантия того, что ошибок в коде не будет. Знакомит с таким критерием охвата, как Modified Condition-Decision Coverage. Но, мне кажется, что если сразу использовать TDD, то таких проблем не будет вообще. По этой методике тяжело написать код, которые не будет покрыт тестами с самого начала. Другое дело, когда человек приходит в проект в или мало тестов, или не было вообще.
Встретил термин граф потока управления. В книге он отображается в виде схемы ветвления кода, что хорошо работает для структурного кода. В объектно-ориентированном коде такой подход уже становится менее наглядным из-за полиморфизма и динамических вызовов. А при использовании Stream API и функциональных цепочек поток управления и вовсе оказывается частично скрыт в библиотечном коде.
Так же в книге уделено внимание, как автор сам называет, граничному и структурному тестированиям. В частности, рассматривается то, как находить границы в данных, для того, что бы уделить им больше внимания. Уделять внимание таким границам надо по тому, что ошибки на границах и при нестандартных условиях возникают чаще. Такое происходит по нескольким причинам:
- краевые случаи;
- специальные значения для типов данных, вроде null;
- границы домена логики приложения, вроде выход за пределы минимального или максимального возраста;
- условия, связанные с производительностью или временем, типа перехода на летнее время или очень больших данных на входе.
Так же причиной проблем может быть неполная спецификация, о чем неоднократно говорится в книге. Но, кроме этого само по себе определение граничных случаев может вызывать сложности, как и надежда на то, что тестирования счастливого пути будет достаточно.
Узнал историю о тестировании с полным покрытием в SQLite и том, что после полного покрытия тестами перестали приходить отчеты о ошибках в Android. Что, в общем-то, очень круто, если учесть количество устройств, которые работают на Android.
Так же в этой главе описывается мутационное тестирование. Еще один вид тестирования, когда правки вносятся уже в исходный код приложения и исследуется реакция тестов на них. Чаще всего, но не обязательно всегда, если тесты не падают, это значит что тесты плохо покрывают затронутый участок кода. В общем, это повод перепроверить тесты, которые покрывают “мутировавший” код. Pitest – один из популярных инструментов с открытым исходным кодом для тестирования мутаций в Java.
Так же автор предлагает не ограничиваться исследованием потока программного кода, а так же исследовать поток данных. То, как данные перемещаются от одного участка кода, к другому. Насколько понял, автор предлагает исследовать то, как данные изменяются в разных участках кода. Правда, ограничивается парой абзацев и ссылается на работу Mauro Pezzè, and Michal Young. 2008. “Software Testing and Analysis: Process, Principles, and Techniques”. Перевода этой книги я не нашел.
Следующая глава посвящена программированию по контракту. Метод, который Bertrand Meyer изложил в своей книге “Object-Oriented Software Construction” 1988, 1997гг.. Он предполагает, что проектировщик должен определить формальные, точные и верифицируемые спецификации интерфейсов для компонентов системы. При этом, кроме обычного определения абстрактных типов данных, также используются предусловия, постусловия и инварианты.
Пока читал, задумался о том, нет ли таких типов данных, как “целые положительные числа” и все такое. Это бы избавило от какой-то части контрактов и проверки граничных значений. Сам в работе чаще всего использую перечисления, что как-то пересекается с идеей контрактов. Начал разбираться и выяснил, что существуют такие типы, как Refinement Types, то есть - уточняющие типы. Это продолжение идеи программирования по контракту, доведенное до логического предела. Ведь, тогда контракт перемещается из тела метода в место создания значения. В том числе это избавляет от написания части тестов.
Другими словами, эту часть материалов я бы пометил, как поверхностную. Выглядит так, что автор не развил тему контрактов, а просто объяснил концепцию и прикрутил к ней способ тестирования :) Отметил, что автор ссылается на книгу “Java. Эффективное программирование. 3-е издание"под авторством Joshua Bloch и на работы Дядюшки Боба, вроде “Чистая архитектура. Искусство разработки программного обеспечения. Наверное, надо будет перечитать…
Что касается тестирования, то автор упоминает такой фреймворк, как Bean Validation (видимо, современная реализация - это Jakarta Validation) и предлагает использовать метод нечеткого тестирования или фаззинга. Так же ссылается на аннотации IntellJ IDEA, вроде @Nullable или @NotNull. Но, этого явно не достаточно для того, что бы раскрыть тему разработки по контрактам. С другой стороны, было несколько ссылок на материал, которые можно изучить, если идеи понравились. Например, автор ссылается на книгу Fuzzing Book, как на источник знаний по нечеткому тестированию, которое рекомендует применять для контрактов. Нашел только ссылку на одноименный сайт: https://www.fuzzingbook.org/. У меня же в коллекции есть другая книга, посвященная этому методу тестирования. Называется “Fuzzing. Исследование уязвимостей методом грубой силы”. Один раз даже пробовал прочитать её, но не осилил. Может быть, доберусь и до неё.
Так же автор предупреждает о том, что некоторые инструменты оценки покрытия кода не верно оценивают утверждения. В частности, этим грешит JaCoCo, что лишний раз говорит о том, что не стоит слепо верить метрикам.
В следующей главе автор рассказывает о тестировании на основе свойств. Для этого, он как раз таки предлагает использовать приложение jqwik, о котором уже говорил раньше. Если кратко, то это генератор аргументов исходя из контрактов. Что-то вроде параметризированных тестов с использованием генератора, вместо жестко заданного набора параметров. С одной стороны - это удобно, но не представляю себе это в пайплайне. Если задать много итераций, то пайплайн начнет тормозить, если мало - то нет гарантии, что будут покрыты требуемые кейсы. Выглядит так, что придется добавлять дополнительный пайплайн для ночных сборок, например? Тут придется подумать, в общем, а автор (пока) тему CI обходит стороной. И да, еще могут быть проблемы с повторяемостью. Например, я привык к тому, что проблему прежде всего надо повторить, а потом уже решать, а работая с сгенерированными аргументами придется вести подробные логи и можно представить себе их объем.
Впрочем, автор упоминает эту проблему немного в другом контексте, как дорогой или иногда просто невозможный процесс, так как может быть необходимо генерировать большие наборы данных. Так же проблемой являются граничные значения, которые надо обязательно учитывать при генерации на основе свойств. Ну, и есть для некоторых методов просто невозможно подставлять случайно сгенерированные данные в виду связанности аргументов. Например, координаты треугольника должны быть валидными (связанными), а не случайными.
Забавно то, что автор сам признается в том, что редко пишет такой тип тестов, по тому что считает что как правило тестов на основе примеров как правило достаточно. И только после того, как тестов на основе примеров кажется недостаточно, автор добавляет тесты на основе свойств.
Следующая глава посвящена тестовым дублерам. Речь пойдет о dummy objects или “объекты-пустышки”, fake objects или фиктивных объектах, stubs или заглушках, mock objects или иммитациях и spies или шпионах. На пример использования фреймворка Mockito автор показывает, как работать с каждым типом дублера отдельно.
В конце главы автор рассуждает о том, что использование дублеров до сих пор вызывает споры в профессиональной среде и ссылается на книгу “Делай как в Google. Разработка программного обеспечения”, как на материал для исследования. Основная претензия к имитациям заключается в том, что они не полностью повторяют поведение оригинала, не успевают за изменениями и в целом делают тесты более хрупкими. Некоторые разработчики твердо убеждены, что применение имитаций может привести к созданию наборов тестов, проверяющих имитацию, а не код. Безусловно, когда надо проверить сложные сценарии или интерактивное поведение, вместо состояния, когда надо проверить работу с внешне нестабильными или медленными сервисами, то имитации очень помогают. Так что, их следует применять осознанно, отдавая предпочтение более простым и надёжным тестовым дублёрам или реальным объектам там, где это возможно.
В следующей главе автор рассуждает о проектировании с учетом простоты тестирования. Прежде всего, он вводит такой определение, как тестируемость, степень простоты разработки автоматизированных тестов для тестируемой системы, класса или метода. И дальше рассуждает о структуре кода, отделении бизнесс-части от инфраструктуры, о гексагональной архитектуре и прочем, о чем пишут, например, Robert Martin в “Чистой архитектуре” и Eric Evans в Предметно-ориентированном проектировании”. Так же автор часто вспоминает о таком паттерне, как Dependency Injection и категории Inversion of Control в целом, использование которых помогает писать код, который проще тестировать. Хотя, конечно, это просто приятный бонус, а не основная цель.
В целом, главу можно сократить до одной мысли - хорошо написанный код легко использовать, в том числе и в автоматических тестах. А вот как написать хороших код, лучше прочитать у корифеев. Хотя, в книге тоже хорошо подан материал, но только как знакомство с идеями, так как одной главы - мало.
В следующей главе автор кратко описывает TDD, разработку через тестирование. Прикольно то, что он практически сразу же начинает применять параметризированные тесты, что мне не понравилось. Не понравилось по тому, что автор в книге знакомит людей с методами тестирования и мне кажется, что учить надо по канону, в первую очередь, а до всех этих сокращений, упрощений и ускорений читали дойдут сами, со временем. Все эти параметризированные тесты и “сжатые итерации” могут исказить представление о сути TDD. В общем, если вас заинтересует эта методика, то я настоятельно рекомендую прочитать книгу “Экстремальное программирование. Разработка через тестирование”.
Следующую главу автор посвятил большим тестам, подразумевая под ними интеграционные и системные тесты. И тут снова не могу сказать, что мне понравился материал. С одной стороны, тут не может быть какого-то одного простого решения, начиная с момента когда начинать эти тесты, заканчивая тем, каким объемом кода ограничиться. Понятно, что есть универсальная мысль - чем меньше скоуп, тем лучше, во всех отношениях, а вот дальше уже начинаются ньюансы. Тесты, которые затрагивают большое количество компонентов, как правило хрупкие, сложны в разработке и сопровождении, плохо понятны новым разработчикам и со временем просто умирают. А уж если они становятся flaky-тестами, то вообще их проще выкинуть сразу. В общем, мне кажется что все эти сложные тесты, включая приемочные, должны писать какие-то другие люди, может быть отдел QA, не знаю. Для разработки их полезность надо вначале доказать, а уж есть получится, то заниматься ими…
Часть главы автор посветил тестированию работы с реляционными базами данных, посредством тестирования SQL-запросов, что мне вообще кажется странным и я, честно говоря, сильно не вчитывался в этот материал. А дальше был Selenium, Cucumber и все то, что я хорошо знаю из книги “BDD в действии. Второе издание”, которую и порекомендую. Даже если сама по себе методика вам не понравится, то та часть, которая посвящена работе с инструментами может пригодится. И уж там точно этого материала больше, чем в описываемой главе. Но, это не проблема книги, конечно и автор правильно сделал, что познакомил читателей с этими инструментами и в целом, материалом. Для себя отметил еще один фреймворк для роботизированной автоматизации процессов - Robot.
Следующая глава посвящена качеству тестового кода. И тут я с автором согласен, и с тем, что тесты должны быть быстрыми, что тесты должны быть изолированными, и прочая, и прочая. Хорошая получилась глава, практически чеклист. По-поводу того, что тесты должны быть быстрыми, не плохо разобрано в книге “Грокаем continuous delivery”. Да и вообще, эти книги не плохо читать в связке. А вот книгу, которую в этой главе советует автор, “Шаблоны тестирования xUnit. Рефакторинг кода тестов” еще не читал. Взял на заметку, так сказать.
В заключении автор снова приводит схему с рабочим процессом разработчика подразумевая, что теперь читатель должен посмотреть на неё с другой стороны, со стороны полученных после прочтения книги знаний. Прикольно то, что в заключении автор упоминает о нефункциональном тестировании и отсылает к книге “Фуллстек тестирование. Создаем качественные программы”, которая есть у меня и я решил как раз её взять следующей. И попутно вспомнил о еще одной книге, которая посвящена тестированию в Google и так и называется, “Как тестируют в Google”. Есть в электронной библиотеке. Выглядит так, что получается целая серия, правда не уверен что имеет смысл сейчас её читать.
Уже позже понял, что вообще нет ничего о AI, даже полуслова, хотя в момент написания книги он уже набирал популярность. Не то, что бы я был фанатом, но хотя бы познакомить с методами внедрения, опытом использования и всего такого - можно было бы. Энивей, книгу оцениваю на 5 из 5 не за глубину проработки каждой темы, а за то, что она честно и последовательно выполняет свою задачу. Это хорошее системное введение в тестирование для разработчиков, которое даёт целостную картину, знакомит с ключевыми подходами, показывает их ограничения и постоянно отсылает к более глубоким источникам. Книга расширяет кругозор, помогает навести порядок в уже известных практиках и служит удобной отправной точкой для дальнейшего изучения, а именно этого от неё и ожидаешь.
Что касается качества издания, то это мне оно нравится, не смотря на то что это компьютерная печать, а значит клееная книга. Пока у меня с ними проблем не было и надеюсь, что не будет. Взамен я получаю твердый переплет, цветные иллюстрации, качественную печать на прекрасной бумаге. Мне очень!
Ссылка на github: https://github.com/effective-software-testing/code
Автор(ы):
- Mauricio Aniche
Год издания: 2023
Количество страниц: 370
Оценка: 5/5
Издатель: ДМК Пресс
Ссылка на страницу книги на сайте издательства: https://dmkpress.com/catalog/computer/programming/978-5-97060-997-2/
Оригинальное название: Effective Software Testing: A developer’s guide
Год издания оригинала: 2022